Prime Intellect builds decentralized training ground for AI models
The startup wants to turn scattered GPUs around the world into a unified training network for open-source AI, and it's already done it twice.
Training a frontier AI model typically requires tens of thousands of GPUs humming in unison inside a single data center owned by a company with a market cap larger than most countries. Prime Intellect thinks that’s a problem worth solving.
The startup, founded by Vincent Weisser and Johannes Hagemann, is building a decentralized platform designed to aggregate computing power from around the globe and channel it into training, evaluating, and deploying large language models. Think of it as turning the world’s idle hardware into one giant, distributed supercomputer, except the machines don’t need to be in the same building, the same country, or even the same continent.
What Prime Intellect has actually built
Plenty of projects promise decentralized AI infrastructure. Most of them are still at the whitepaper stage. Prime Intellect has already run two major training experiments, which puts it meaningfully ahead of the curve.
The first, called INTELLECT-1, produced a 10-billion-parameter language model trained entirely on globally distributed compute. The company describes it as the first open-source decentralized LLM training run conducted at scale. For context, 10 billion parameters is not trivially small. It’s roughly the size of models that were considered state-of-the-art just a few years ago.
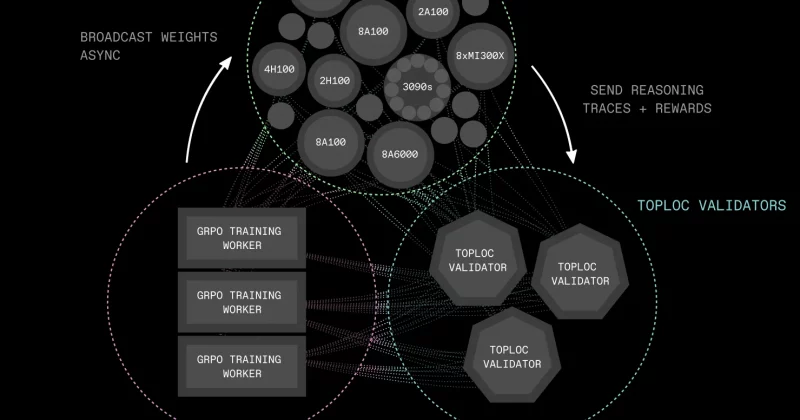
The second experiment, INTELLECT-2, was more ambitious. This one produced a 32-billion-parameter model trained using fully asynchronous reinforcement learning. That last detail matters a lot.
Here’s the thing about training AI models across distributed hardware: the machines need to coordinate constantly. In a centralized data center, that coordination happens over ultra-fast internal networks. When your GPUs are spread across the planet, latency becomes a nightmare. Traditional synchronous training, where every machine waits for every other machine before proceeding, simply breaks down.
In English: imagine trying to run a relay race where your teammates are in different time zones and you have to wait for each of them to finish their leg before anyone can start the next one. It doesn’t scale.
Prime Intellect’s solution is a framework called PRIME-RL, which enables asynchronous reinforcement learning. Instead of forcing every node to stay in lockstep, machines can contribute their work at their own pace. The framework is designed for both scalability and robustness, meaning individual nodes can drop out or slow down without torpedoing the entire training run.
The Lab platform and why it matters
Beyond the headline training experiments, Prime Intellect has developed what it calls the Lab platform. This is an integrated environment for managing large-scale AI training workflows, specifically geared toward agentic reinforcement learning and post-training research.
The value proposition is straightforward. Running serious AI training today requires navigating a maze of infrastructure complexity: provisioning GPU clusters, managing distributed systems, handling fault tolerance, orchestrating data pipelines. The Lab platform aims to abstract away much of that operational overhead.
For researchers who don’t have access to massive GPU clusters, and that’s most researchers, this kind of tooling could meaningfully lower the barrier to entry for cutting-edge AI work. It’s one thing to publish an algorithm. It’s another thing entirely to actually run it at scale without a nine-figure compute budget.
The platform integrates components for agentic RL specifically, which positions it at the intersection of two of the hottest areas in AI research right now: reinforcement learning from human feedback and autonomous agent development.
The governance question
Prime Intellect currently operates as a Delaware C-corp, the standard legal structure for venture-backed startups. But the founders have signaled plans to eventually adopt something closer to Ethereum’s decentralized governance model.
That’s an interesting aspiration, though it comes with obvious tension. Decentralized governance works best when the community of stakeholders is large and engaged. Ethereum didn’t start with decentralized governance either. It evolved into it over years as the ecosystem matured.
The comparison to Ethereum is instructive in another way too. Ethereum succeeded partly because it gave developers a reason to build on it before governance questions were fully resolved. Prime Intellect seems to be following a similar playbook: ship working infrastructure first, decentralize the decision-making later.
Whether a hybrid AI-infrastructure company can actually pull off that transition remains an open question. The crypto world has seen plenty of projects promise decentralization and then quietly shelve the idea once the founding team realizes how much easier it is to make decisions with five people in a room.
What this means for investors and the broader market
The AI infrastructure market is defined by a single dominant dynamic: compute scarcity. The companies that can train the biggest models are the companies that can afford the most GPUs. That concentration of resources naturally favors incumbents like OpenAI, Google, and Anthropic, all of which have secured billions of dollars in compute commitments.
Prime Intellect’s bet is that decentralized training can disrupt that dynamic by unlocking hardware that would otherwise sit idle. If the approach works at frontier scale, not just at 10B or 32B parameters but at hundreds of billions, it could fundamentally alter the economics of AI development. Smaller organizations could pool resources to compete with well-funded labs.
The risk is equally clear. Asynchronous distributed training introduces efficiency losses compared to centralized approaches. A model trained across scattered hardware may take longer, cost more per unit of compute, or produce slightly worse results than the same model trained in a purpose-built cluster. Prime Intellect’s PRIME-RL framework is designed to minimize those tradeoffs, but minimizing and eliminating are different things.
The open-source angle adds another dimension. By releasing models trained on their platform as open-source, Prime Intellect aligns itself with the growing movement to keep AI development transparent and accessible. That’s a strategic choice, not just an ideological one. Open-source models attract contributors, researchers, and ecosystem builders in ways that proprietary ones don’t.
For anyone watching the decentralized AI infrastructure space, Prime Intellect stands out for a simple reason: it has actually trained models, not just talked about training them. Whether the 32B-parameter INTELLECT-2 can compete with models from centralized labs on benchmark performance is a different, harder question. But as a proof of concept for decentralized training at meaningful scale, it’s the most tangible evidence the space has produced so far.