Google paper advocates for LLMs to express uncertainty clearly
New research from Google introduces a metric for measuring whether AI models honestly communicate what they don't know, with implications for anyone relying on AI-generated analysis.
Google Research has published a paper arguing that large language models need to get much better at one deceptively simple task: admitting when they’re not sure about something.
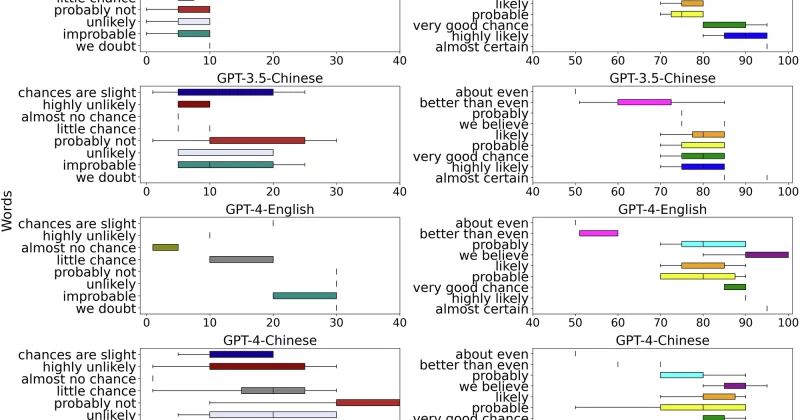
The paper, titled “Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?”, finds that current LLMs are remarkably bad at matching their verbal confidence to their actual internal certainty.
The gap between confidence and competence
Authored by Gal Yona and Roee Aharoni of Google Research, along with Mor Geva from Google Research and Tel Aviv University, the paper was first submitted in May 2024 and revised in September 2024. It was presented at EMNLP 2024, one of the top venues for natural language processing research.
The core contribution is a new metric called “faithful response uncertainty.” It measures the gap between how confident a model actually is in its answer (based on its internal probabilistic outputs) and how confidently it phrases that answer in plain language.
The researchers focused specifically on knowledge-intensive question-answering tasks, the kind of scenarios where a model is expected to retrieve and synthesize factual information. Their recommendation is straightforward: models should hedge their responses when their internal outputs conflict. Instead of stating an uncertain answer as fact, a model should say something like “I’m not sure, but I think…” when its own probability distributions suggest genuine doubt.
Current fine-tuning and reinforcement learning techniques tend to reward models for sounding helpful and definitive. Saying “I’m not confident” doesn’t score well when your training objective is optimized for user satisfaction.
Why hallucinations persist
The faithful response uncertainty metric gives researchers a concrete way to measure this problem. Rather than just evaluating whether answers are correct or incorrect, it evaluates whether the model’s stated confidence matches its computed confidence.
The paper identifies current alignment techniques as insufficient for solving this problem. The methods used to make LLMs more helpful, more harmless, and more honest don’t adequately address the calibration of expressed uncertainty. The authors frame this as a gap that needs dedicated research attention.
Similar investigations into uncertainty quantification in AI have continued to expand as a field of study, suggesting that Google’s research is part of a broader recognition that this problem can’t be ignored.
What this means for anyone using AI for decisions
The practical path forward involves integrating uncertainty expression into the model alignment process itself. Rather than treating confidence calibration as an afterthought, it needs to be a core training objective. Models that can reliably communicate “I’m confident about this part but uncertain about that part” would represent a genuine step forward in AI trustworthiness.